从手写数字识别开启人工智能的大门(附源码)
前言
在传统程序中,是通过编码定义好规则,为程序提供一个输入,程序通过规则产生输出,如果一个程序只是枚举所有的输入,来产生相应的输出,那可能根本算不上“智能”,因为未知的输入太多,而且也不现实,比如围棋的棋谱就是千变万化的。
对于AI(人工智能)技术来说,恰恰相反,是通过已知的输入和输出,来生成规则,程序通过大量样本数据的训练,使之越来越“明白”这个规则,从而能够预测未知输入的结果,这就是所谓的“监督学习”。
图片存储在计算机中就是一堆毫无意义的二进制数据,计算机只会处理数据(所谓处理数据不过是将这些二进制数据转变成电子信号量在计算机电路中疯狂运转),并不知道图片的具体含义,只有人可以看懂图片,所以这就是很多网站采用验证码的方式来区分人和机器的原因。
让计算机认识图片就是AI的一个重要领域-机器视觉,基于Tensorflow2.0框架的发布,利用深度学习来实现一个AI已经变得越来越简单。
效果展示
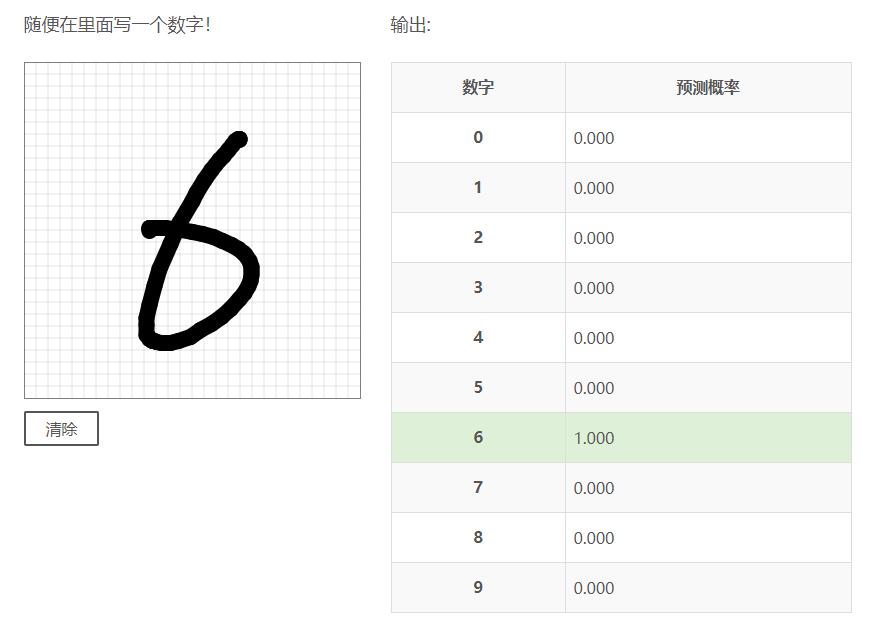
随便在里面写一个数字!
输出:
| 数字 | 预测概率 |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |
原理
手写数字是人工智能在图像识别领域的一个经典例子,图片在计算机里的存储是以像素表示的rgb颜色代码,不同的人从0到9写这十个数字是不一样的,即使是同一个人也不可能写出2个一摸一样的数字,也就是说对于只有1笔的数字1,图片像素也会不同,但是像素里面肯定是有一定特征的,否则人也不会认识了!那么我们现在要解决的问题就是让计算机从存储的像素中找到这个特征,然后把它规到0到9这十个分类里面。
如何找到这个特征?通过大量的数学计算,简单来说,就是你手写的数字,以图片方式录入计算机变成一堆数字,然后通过一系列的函数计算,生成一个概率分布,这个概率分布加起来的总和是1,而这里面概率最大的就是程序预测的结果,构造这一系列函数就叫做构建模型。
比如我们初中都学过的线性函数$ y=ax+b $,x是输入,y是输出,现在事先知道了x和y的值需要求a和b的值,知道了越多的x和y,a和b就越精确,像这个函数我们只要知道2对(x,y)就可以利用二元一次方程求出(a,b)。
而在深度学习的模型中就包括大量类似的函数,也就包括大量的a和b,这些变量就是训练参数,一开始参数的值是随机的,通过样本数据,比如我给定一张图,上面画了一个2,同时告诉程序这个是2,那么程序在计算过程中就会往2的概率靠拢,如何靠拢,通过一个叫损失函数的函数,来计算和2之间的差距,再通过一个叫优化函数的函数去调整模型中的训练参数,从而使损失函数的值越来越小,也就是使输出越来越接近2,光接近2还不行,当我画了一个3,还要能接近3,同时不要影响之前算好的2的结果,这个过程就叫做训练模型。那么得调整多少个这样的训练参数才能达到这个要求,以我们这个手写数字的模型为例,它包含了100万个训练参数。
为什么叫深度学习?如果把每个函数比作一个神经元(不同的函数对同样的输入会产生不同的输出,就好比不同的神经元对同样的刺激有不同的反应),这些函数按层次划分,除了输入层和输出层之外,中间还包括了大量隐藏层,像神经网络一样结合起来。
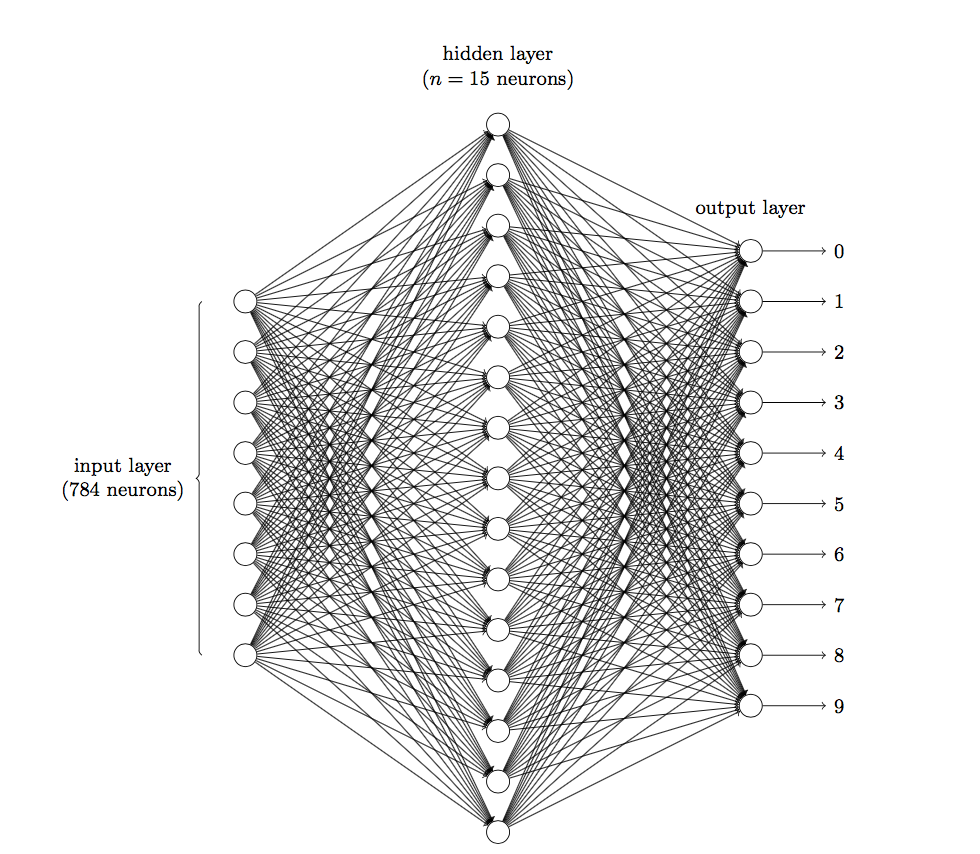
通过给大量的数据打上标签,提交给模型训练,从而使模型越来越拟合真实数据。
对于图像识别,计算机科学家们已经泛化出了卷积神经网络(CNN)模型,可以应对图像特征提取的通用问题,我们可以依赖这个理论来搭建模型。
比如著名的卷积神经网络模型VGG(Visual Geometry Group):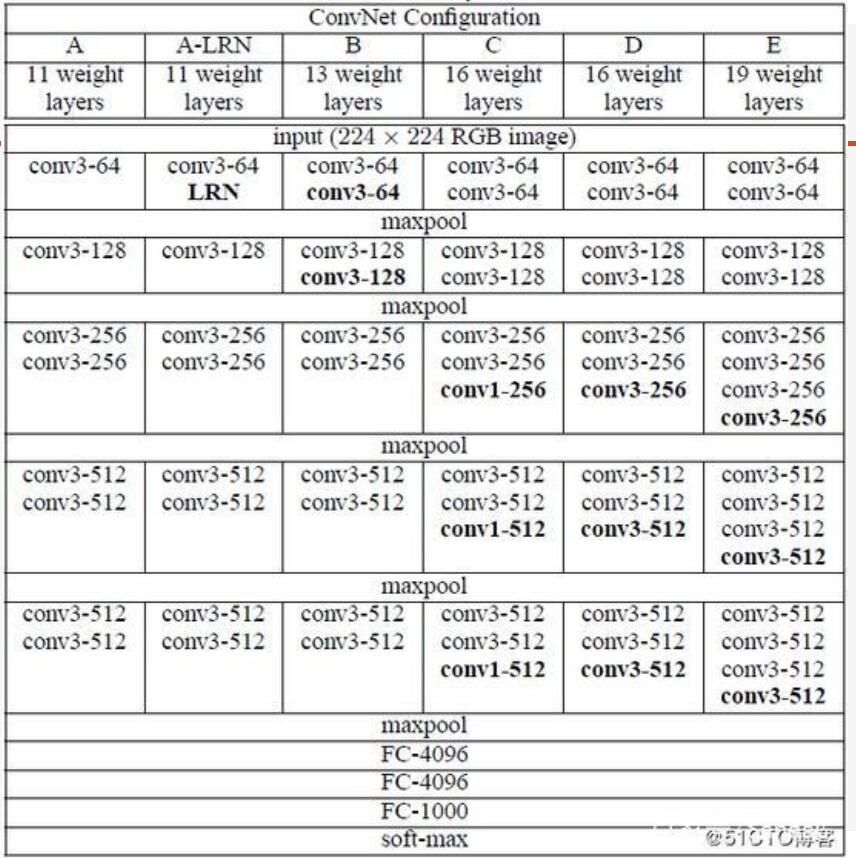
实现
简单来说,实现一个图像识别AI仅需要3个步骤:
- 得到大量带标签的图片样本
- 构建神经网络模型
- 训练模型
Tensorflow2.0内置的API已经抽象了大量的底层数学运算,同时也提供了训练数据集
构建训练数据集
1 | |
当调用tf.keras.datasets.mnist.load_data()后,样本数据集会自动从网络中下载。
构建卷积神经网络模型
简单版的CNN模型
1 | |
训练模型
1 | |
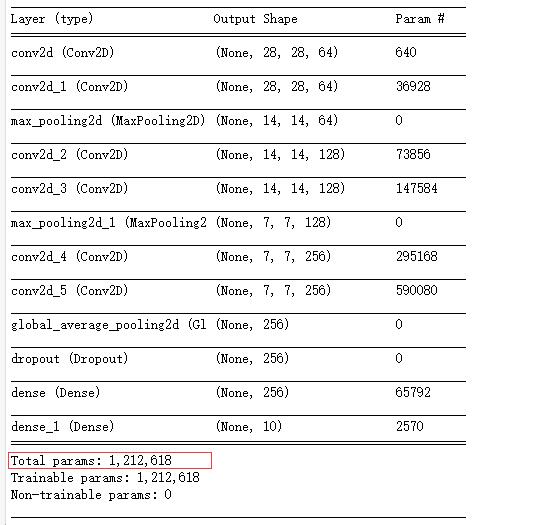
可以看到这个模型有1,212,618个变量,由于本人电脑没有GPU,只能依赖CPU运算,一次训练需要8-10分钟,总共训练了10次,最终正确率在测试数据集上达到了99.44%。GPU驱动的底层运算和模型训练有很多通用的数学计算,所以采用GPU训练可以大大加快训练速度。如果没有条件,也可以托管kaggle这个网站训练。

结语
虽然这个程序只能识别10个数字,不过我们简简单单就实现了一个具备学习能力的人工智能了。
引用网上的一张图片,当你说你在用深度学习做人工智能的时候:

完整代码
生成模型
1 | |
之后便可以加载模型,然后使用模型进行预测:
1 | |
关于怎么在html页面上运行tensorflow,可以参考我另一篇文章:将训练好的Tensorflow模型部署到Web站点。

